こんにちは。お久しぶりです。
新しい会社に移ってから、約半年が経過しました。
周りの皆様はとてもレベルが高く、大変素晴らしい環境でお仕事をさせていただいております。
本当に心の底から転職して良かったな、と感じる今日この頃です。
さて、本日は、とあるシステムの構築に携わらせていただき、Terraform の CI 機構を CodeBuild / GitHub App / tfnotify で作る機会があったので、その際の備忘録をツラツラと残しておこうと思います。
作るもの
構成
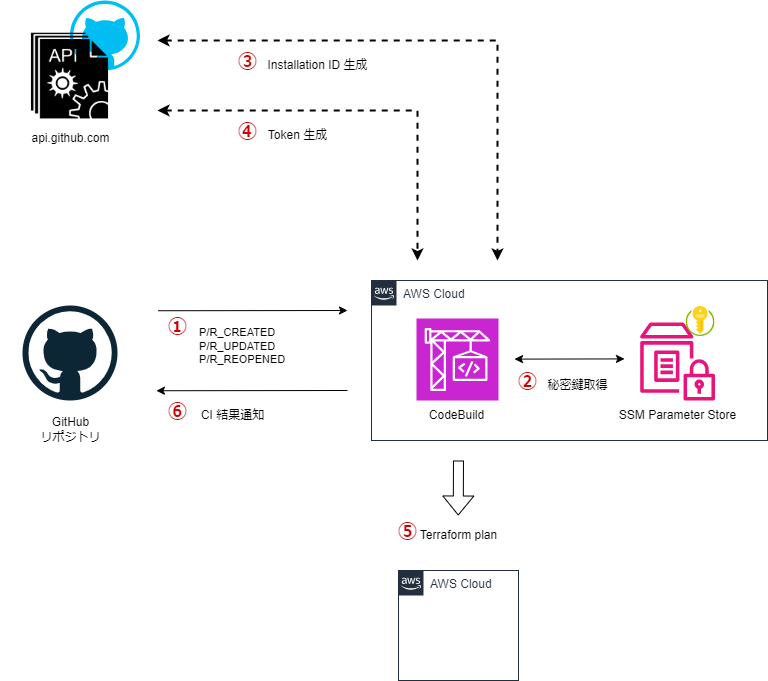
Terraform のコード自体は GitHub のリポジトリでホストされていることを前提とします。
Pull Request の作成、更新時に CodeBuild を Hook して Terraform を実行し、plan 結果を Pull Request のコメントとして通知します。
詳細なシーケンスは以下の通りです。
① PR の作成、更新をトリガーに CodeBuild を起動。
② CodeBuild が SSM Parameter Store に格納された GitHub App の秘密鍵を取得
③ GitHub App の秘密鍵から JWT を生成し、 API を叩いて Installation ID を生成
④ Installation ID を指定して API を叩き、Access Token を生成
⑤ terraform plan を実行
⑥ plan 結果を tfnotify に渡して Pull Request に通知
⑦ Access Token を無効化
ディレクトリ構成
.
├── deploy_scripts
│ └── ci
│ ├── .tfnotify.yml
│ ├── bin
│ │ ├── create_github_token.sh
│ │ ├── install_terraform.sh
│ │ ├── install_tfnotify.sh
│ │ ├── plan_tfnotify.sh
│ │ └── revoke_github_token.sh
│ └── buildspec.yml
└── env
└── dev
├── resource1
│ ├── 00_backend.tf
│ ├── 00_provider.tf
│ └── vpc.tf
├── resource2
│ ├── 00_backend.tf
│ ├── 00_provider.tf
│ └── vpc.tf
└── resource3
├── 00_backend.tf
├── 00_provider.tf
└── vpc.tf
Terraform のコードは /env/dev/resource[1 – 3] 配下の 3 つをエントリーポイントとするディレクトリ構成を前提とします。
また、/deploy_scripts/ci/bin 配下に GitHub App より Token を発行するスクリプトや、Terraform の実行結果を通知するためのユーティリティスクリプトを配置します。
buildspec.yml
CodeBuild の処理を定義する buildspec.yml は以下の通りです。
---
version: 0.2
phases:
install:
runtime-versions:
golang: latest
commands:
- /bin/bash ${CODEBUILD_SRC_DIR}/deploy_scripts/ci/bin/install_terraform.sh
- /bin/bash ${CODEBUILD_SRC_DIR}/deploy_scripts/ci/bin/install_tfnotify.sh
pre_build:
commands:
- export APP_ID=$(aws ssm get-parameter --name ${APP_ID_SSM_ARN} --with-decryption --query Parameter.Value --output text)
- export APP_SECRET=$(aws ssm get-parameter --name ${APP_SECRET_SSM_ARN} --with-decryption --query Parameter.Value --output text)
- export GITHUB_TOKEN=$(/bin/bash ${CODEBUILD_SRC_DIR}/deploy_scripts/ci/bin/create_github_token.sh)
- export REPO_OWNER=$(echo $REPO_FULL_NAME | cut -d '/' -f 1)
- export REPO_NAME=$(echo $REPO_FULL_NAME | cut -d '/' -f 2)
- sed -i "s/<OWNER>/$REPO_OWNER/g; s/<NAME>/$REPO_NAME/g" ${CODEBUILD_SRC_DIR}/deploy_scripts/ci/.tfnotify.yml
- cd ${CODEBUILD_SRC_DIR}
- terraform fmt -no-color -check -diff -recursive
build:
commands:
- |
if git --no-pager diff origin/main..HEAD --name-only | grep -E '^env/dev/resource1/'; then
/bin/bash ${CODEBUILD_SRC_DIR}/deploy_scripts/ci/bin/plan_tfnotify.sh /env/dev/resource1/
fi
- |
if git --no-pager diff origin/main..HEAD --name-only | grep -E '^env/dev/resource2/'; then
/bin/bash ${CODEBUILD_SRC_DIR}/deploy_scripts/ci/bin/plan_tfnotify.sh /env/dev/resource2/
fi
- |
if git --no-pager diff origin/main..HEAD --name-only | grep -E '^env/dev/resource3/'; then
/bin/bash ${CODEBUILD_SRC_DIR}/deploy_scripts/ci/bin/plan_tfnotify.sh /env/dev/resource3/
fi
post_build:
commands:
- /bin/bash ${CODEBUILD_SRC_DIR}/deploy_scripts/ci/bin/revoke_github_token.sh
CodeBuild の処理自体は、先のシーケンスと同等です。
差分のあったディレクトリの plan 結果のみを通知するように、build ステージで main ブランチとの diff を取ってから、検知したディレクトリのみ Terraform の実行と通知処理を行います。
.tfnotify.yml
GitHub への通知を行うため tfnotify を用います。
通知内容のカスタマイズも可能で、以下のように yaml ファイルへ通知内容を記述し、 CLI 実行時の引数として渡してあげます。
※ <OWNER> と <NAME> は、先の buildspec.yaml の処理 ( 16 – 18 行 ) にて適切なリポジトリ情報で置換されます。
---
ci: codebuild
notifier:
github:
token: $GITHUB_TOKEN
repository:
owner: "<OWNER>"
name: "<NAME>"
terraform:
plan:
template: |
{{ .Title }} for {{ .Message }} <sup>[CI link]( {{ .Link }} )</sup>
{{if .Result}}
<pre><code> {{ .Result }}
</pre></code>
{{end}}
<details><summary>Details (Click me)</summary>
<pre><code>
{{ .Body }}
</pre></code>
</details>
when_add_or_update_only:
label: "add-or-update"
when_destroy:
label: "destroy"
template: |
## :warning: WARNING: Resource Deletion will happen :warning:
This plan contains **resource deletion**. Please check the plan result very carefully!
when_plan_error:
label: "error"
Utility scripts
CLI の導入、Token の発行、通知等々のスクリプトを以下のように用意します。
※ クリックで展開します。
▶ install_terraform.sh
#!/bin/bash
####################################
# This script is used by CodeBuild #
####################################
set -euxo pipefail
TFVERSION="1.7.3"
git clone https://github.com/tfutils/tfenv.git $HOME/.tfenv
ln -s $HOME/.tfenv/bin/* /usr/local/bin
tfenv install ${TFVERSION} && tfenv use ${TFVERSION}
terraform version
▶ install_tfnotify.sh
#!/bin/bash
####################################
# This script is used by CodeBuild #
####################################
set -euxo pipefail
TNVERSION="v0.8.0"
wget https://github.com/mercari/tfnotify/releases/download/${TNVERSION}/tfnotify_linux_amd64.tar.gz
tar xzf tfnotify_linux_amd64.tar.gz
cp tfnotify /usr/local/bin/
tfnotify
▶ plan_tfnotify.sh
#!/bin/bash
####################################
# This script is used by CodeBuild #
####################################
set -euxo pipefail
echo "Run Terraform plan in ${CODEBUILD_SRC_DIR}/${1}/."
cd ${CODEBUILD_SRC_DIR}/${1}/ && \
terraform init && \
terraform plan -no-color | tfnotify --config ${CODEBUILD_SRC_DIR}/deploy_scripts/ci/.tfnotify.yml plan --message "${1}"
echo "Terraform plan executed in ${CODEBUILD_SRC_DIR}/${1}/."
▶ create_github_token.sh
#!/bin/bash
####################################
# This script is used by CodeBuild #
####################################
base64url() {
openssl enc -base64 -A | tr '+/' '-_' | tr -d '='
}
sign() {
openssl dgst -binary -sha256 -sign <(printf '%s' "${APP_SECRET}")
}
header="$(printf '{"alg":"RS256","typ":"JWT"}' | base64url)"
now="$(date '+%s')"
iat="$((now - 60))"
exp="$((now + (3 * 60)))"
template='{"iss":"%s","iat":%s,"exp":%s}'
payload="$(printf "${template}" "${APP_ID}" "${iat}" "${exp}" | base64url)"
signature="$(printf '%s' "${header}.${payload}" | sign | base64url)"
jwt="${header}.${payload}.${signature}"
installation_id="$(curl --location --silent --request GET \
--url "https://api.github.com/repos/${REPO_FULL_NAME}/installation" \
--header "Accept: application/vnd.github+json" \
--header "X-GitHub-Api-Version: 2022-11-28" \
--header "Authorization: Bearer ${jwt}" \
| jq -r '.id'
)"
token="$(curl --location --silent --request POST \
--url "https://api.github.com/app/installations/${installation_id}/access_tokens" \
--header "Accept: application/vnd.github+json" \
--header "X-GitHub-Api-Version: 2022-11-28" \
--header "Authorization: Bearer ${jwt}" \
| jq -r '.token'
)"
echo "${token}"
▶ revoke_github_token.sh
#!/bin/bash
####################################
# This script is used by CodeBuild #
####################################
curl --location --silent --request DELETE \
--url "https://api.github.com/installation/token" \
--header "Accept: application/vnd.github+json" \
--header "X-GitHub-Api-Version: 2022-11-28" \
--header "Authorization: Bearer ${GITHUB_TOKEN}"
AWS Resources
構成図にある CodeBuild 関連のリソースですが、こちら に Terraform の module を用意しました。
以下のように呼び出すことで必要なリソースがプロビジョニングされます。
※ GitHub App の ID と 秘密鍵 は SSM Parameter Store に SecureString として手動で登録しておき、その ARN を CodeBuild の環境変数 ( APP_ID_SSM_ARN, APP_SECRET_SSM_ARN ) として設定しておきます。
※ クリックで展開します。
▶ 呼び出しサンプル
module "cicd_terraform_ci_github" {
source = "git::https://github.com/snkk1210/tf-m-templates.git//modules/aws/cicd/terraform/ci/github"
common = {
"project" = "sample"
"environment" = "sandbox"
"service_name" = "hcl"
"type" = "ci"
}
source_info = {
location = "https://github.com/<ORGANIZATION_NAME>/<REPOSITORY_NAME>.git"
git_clone_depth = 1
buildspec = "./deploy_scripts/ci/buildspec.yml"
}
environment_variable = {
variables = [
{
name = "APP_ID_SSM_ARN"
value = "arn:aws:ssm:ap-northeast-1:xxxxxxxxxxxx:parameter/path/to/id"
type = "PLAINTEXT"
},
{
name = "APP_SECRET_SSM_ARN"
value = "arn:aws:ssm:ap-northeast-1:xxxxxxxxxxxx:parameter/path/to/secret"
type = "PLAINTEXT"
},
{
name = "REPO_FULL_NAME"
value = "<ORGANIZATION_NAME>/<REPOSITORY_NAME>"
type = "PLAINTEXT"
}
]
}
filter_groups = [
{
event_pattern = "PULL_REQUEST_CREATED"
file_pattern = "^env/dev/*"
},
{
event_pattern = "PULL_REQUEST_UPDATED"
file_pattern = "^env/dev/*"
},
{
event_pattern = "PULL_REQUEST_REOPENED"
file_pattern = "^env/dev/*"
}
]
}
やってみる!!
以下のように /env/dev/resource1 配下のリソースを変更 ( Name タグの更新 ) し、Pull Request を作成します。
diff --git a/env/dev/resource1/vpc.tf b/env/dev/resource1/vpc.tf
index 5360514..415e5ae 100644
--- a/env/dev/resource1/vpc.tf
+++ b/env/dev/resource1/vpc.tf
@@ -2,6 +2,6 @@ resource "aws_vpc" "this" {
cidr_block = "10.10.0.0/16"
tags = {
- Name = "dev-resource1-vpc.0.0.11"
+ Name = "dev-resource1-vpc.0.0.12"
}
}
CodeBuild が起動しました!
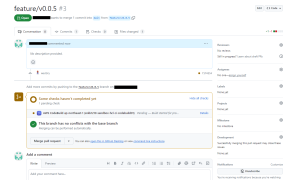
コメントが通知されました!
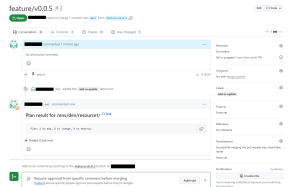
Terraform の実行結果も確認できました!
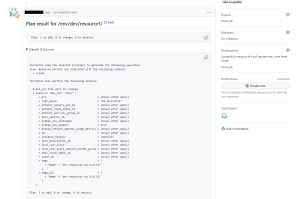
と、いった形で Terraform の CI 機構が完成しました!
終わりに
当初は GitHub の PAT ( Personal Access Token ) をそのまま使って機構を作ろうとしておりました。
しかし、セキュリティリスクの懸念があるのではないか?との指摘をいただいて、GitHub App から一時トークンを生成して利用する構成に変更した経緯があります。
これも新しい職場に転職したおかげで気づけた事柄ですね!!
これからも新天地で頑張っていきます!!
※ 本当に転職して良かった (歓喜)。