
こんにちは。
気づくと既に 2023 年も 1/4 が経過しており、時間の進む速度感覚がおかしくなってきた今日この頃でございます。
さて、とある事情から SES receipt rule で受信したメールを加工して Slack に通知させる必要がでてきました。
具体的には最終的に下記構成のようなパイプラインを構築しようと考えております。
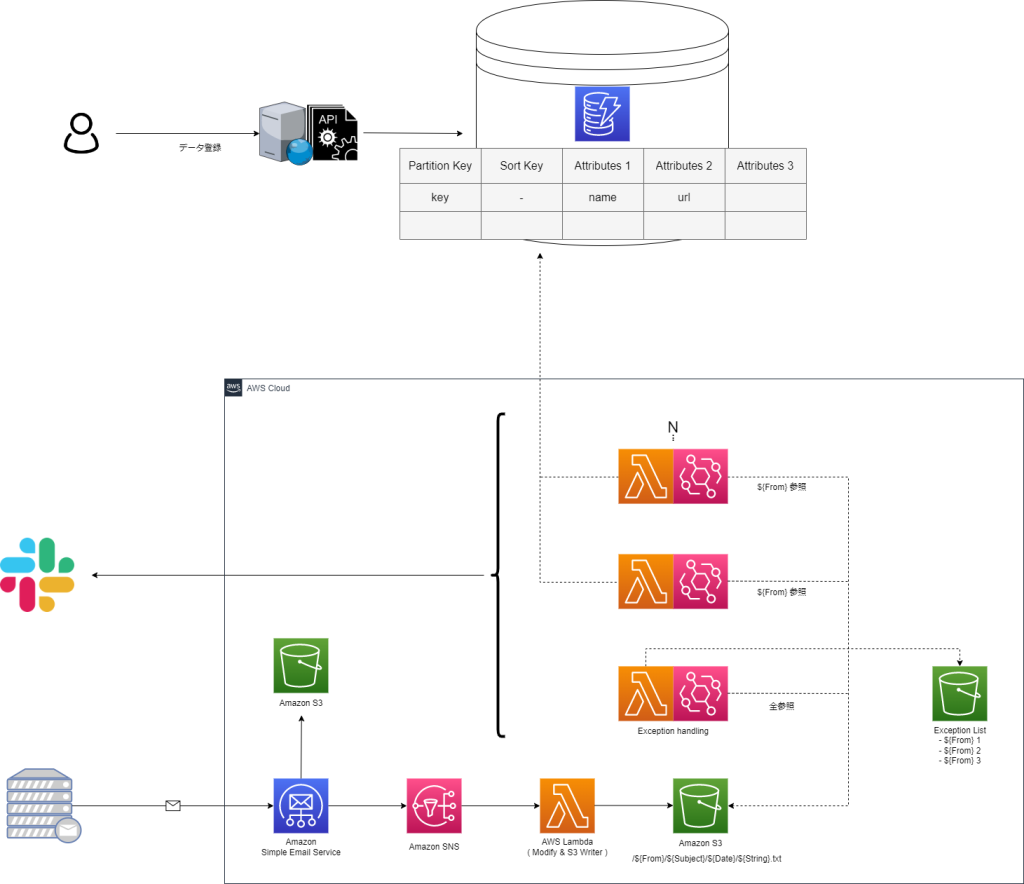
・メール受信時にメール加工用 Lambda を起動し、データを S3 に格納
・特定の From のメールが S3 に格納されたことをトリガーに通知用 Lambda を起動
・別システムのデータベースから情報を引っ張ってきて Slack へ通知
つきましては、この構成の一部を Terraform で管理してみようと思います。
構成図
今回は SES receipt rule → SNS → Lambda → S3 → EventBridge → Lambda までを一括でデプロイできる HCL を作成します。
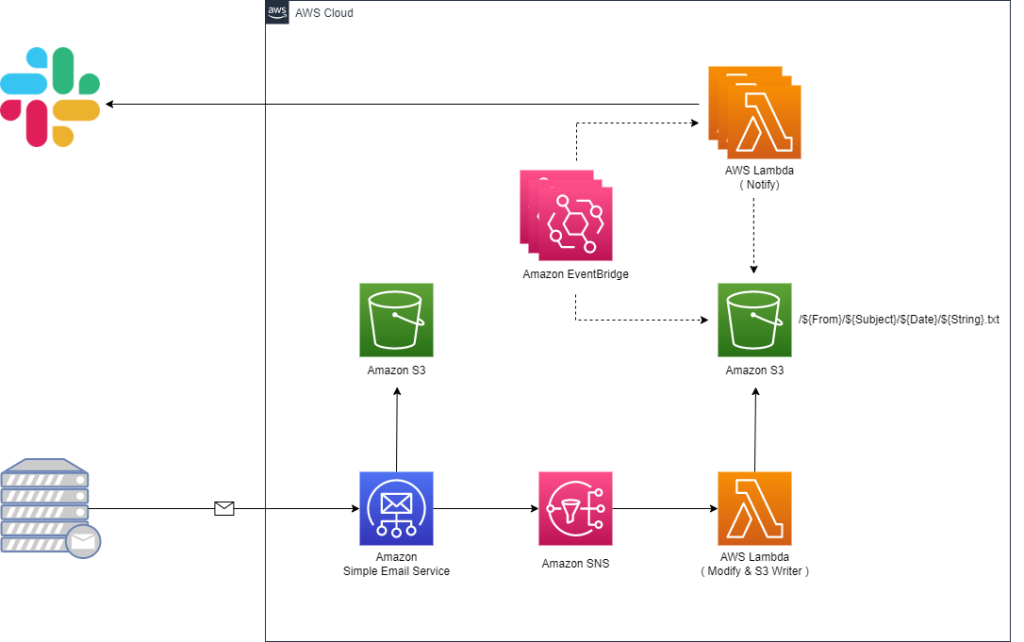
HCL
作成したコード一式は こちら になります。
. ├── README.md ├── example-slack-lambda.tf.example ├── modules │ ├── notifier │ │ ├── eventbridge.tf │ │ ├── example │ │ │ ├── basic │ │ │ │ ├── lambda │ │ │ │ │ ├── bin │ │ │ │ │ └── source │ │ │ │ │ └── basic.py │ │ │ │ ├── lambda.tf │ │ │ │ └── variables.tf │ │ │ └── slack │ │ │ ├── lambda │ │ │ │ ├── bin │ │ │ │ └── source │ │ │ │ └── slack.py │ │ │ ├── lambda.tf │ │ │ └── variables.tf │ │ └── variables.tf │ └── receiver │ ├── lambda │ │ ├── bin │ │ └── source │ │ └── receiver.py │ ├── lambda.tf │ ├── s3-processed.tf │ ├── s3-receiver.tf │ ├── ses-receipt-rule.tf │ ├── sns.tf │ └── variables.tf ├── notifier.tf.example └── receiver.tf.example
modules/ 配下に各種リソース定義を配置し、上位からモジュールを読み込む想定です。
※ .example はモジュール読み込み用のテンプレートです。
以降、要所をツラツラと記載させて頂きます。
Lambda ( メール加工 )
SES で受信したメールを加工する Lambda を用意します。
処理の詳細はメールの From、受信日、件名、本文、表示名を抜き出し、S3 に格納する、とします。
S3 に格納する情報は、後に繋ぎやすいように、本文のみのオブジェクトとし、その他の情報はオブジェクトを格納するディレクトリ名として保持させます。
・modules/receiver/lambda/source/receiver.py
import boto3
import json
import logging
import email
import random
import string
import os
import re
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def lambda_handler(event, context):
logger.info("Event: " + str(event))
message = json.loads(event['Records'][0]['Sns']['Message'])
m_from = message['mail']['commonHeaders']['from'][0]
date = message['mail']['commonHeaders']['date']
subject = message['mail']['commonHeaders']['subject']
content = message['content']
email_obj = email.message_from_string(content)
body = perth_mail_body(email_obj)
logger.info("Body: " + str(body))
fname = extract_mail_address(m_from).replace("/","[slash]") + "/" \
+ subject.replace("/","[slash]") \
+ "/" + date.replace("/","[slash]") \
+ "/" + extract_display_name(m_from) + "[dn]" + randomstr(20) + ".txt"
logger.info("Fname: " + str(fname))
res = put2s3(body, fname)
logger.info("Response: " + str(res))
def perth_mail_body(email_obj):
"""
Retrieve the body part of the mail.
Parameters
----------
email_obj : object structure
Returns
-------
body : string
body part of the mail
"""
body = ""
for part in email_obj.walk():
logger.info("maintype: " + part.get_content_maintype())
if part.get_content_maintype() == 'multipart':
continue
attach_fname = part.get_filename()
if not attach_fname:
charset = str(part.get_content_charset())
if charset:
body += part.get_payload(decode=True).decode(charset, errors="replace")
else:
body += part.get_payload(decode=True)
else:
logger.info("There is Attach File")
body += "Error: Attachments are not supported -> " + str(part.get_payload(decode=True))
return body
def put2s3(body, fname):
"""
Upload files to S3.
Parameters
----------
body : string
File Contents
fname : string
File Name ( Path )
Returns
-------
res : dict
API Return Values
"""
s3 = boto3.client("s3")
try:
res = s3.put_object(
Bucket=os.environ['s3BucketName'],
ACL='private',
Body=body,
Key=fname,
ContentType='text/plain'
)
logger.info("Success: %s has been written.", fname)
logger.info("Success: %s", res)
except Exception as e:
logger.error("Error: %s", e)
return res
def randomstr(n):
"""
Generate a random string.
Parameters
----------
n : int
length of a character string
Returns
-------
: string
random string
"""
return ''.join(random.choices(string.ascii_letters + string.digits, k=n))
def extract_mail_address(m_from):
"""
Extracting email addresses from a string.
Parameters
----------
m_from : string
String containing an email address
Returns
-------
: list
email addresses
"""
pattern = r'[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+'
return re.findall(pattern, m_from)[0]
def extract_display_name(m_from):
"""
Extracting display name from a Mail From.
Parameters
----------
m_from : string
String containing an email address
Returns
-------
: string
display name
"""
delimiter = ' <'
if delimiter in m_from:
idx = m_from.find(delimiter)
logger.info("There is Display Name")
return m_from[:idx]
else:
logger.info("There is no Display Name")
return "no_display_name"
Lambda ( Slack 通知 )
通知用の Lambda は、特定のディレクトリ名 ( メールの From ) 配下にオブジェクトが作成されたことを EventBridge が検知しキックされる想定です。
つきましては、検知させる From 毎に EventBridge と Lambda の組を用意する可能性があったため、モジュール読み込みの際に複数のリソースの組を定義できるように工夫し、且つ、本リポジトリで管理していない Lambda も参照できる形にしています。
※ notifier_groups にリストとして EventBridge と Lambda の組を渡します。
・notifier.tf.example
module "notifier" {
source = "./modules/notifier"
project = var.project
environment = var.environment
notifier_groups = [
{
// Unique identifier
name = "xxxx"
// Triggering buckets
bucket_name = "xxxx"
// Triggering first renovation folder
prefix = "xxxx"
// Lambda Arn
lambda_arn = "xxxx"
// Lambda Function name
lambda_function_name = "xxxx"
},
{
name = "xxxx"
bucket_name = "xxxx"
prefix = "xxxx"
lambda_arn = "xxxx"
lambda_function_name = "xxxx"
},
{
name = "xxxx"
bucket_name = "xxxx"
prefix = "xxxx"
lambda_arn = "xxxx"
lambda_function_name = "xxxx"
}
]
}
Slack 通知用の Lambda は EventBridge から渡されたオブジェクトを読み込み、適宜整形して Slack の WebhookURL にリクエストを発行する流れとなります。
From の種類ごとに、異なった処理を行う Lambda 関数を用意する想定なので、1 サンプルとして基本的な Lambda 関数をリポジトリに配置しています。
・modules/notifier/example/slack/lambda/source/slack.py
import boto3
import json
import logging
import os
import re
from base64 import b64decode
from urllib.request import Request, urlopen
from urllib.error import URLError, HTTPError
from urllib.parse import quote
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def lambda_handler(event, context):
logger.info("Event: " + str(event))
bucket_name = str(event['detail']['bucket']['name'])
logger.info("Bucket: " + str(bucket_name))
object_key = event['detail']['object']['key']
object_list = event['detail']['object']['key'].split("/")
for i in object_list:
logger.info("Object: " + str(i))
m_from = object_list[0]
subject = object_list[1]
date = object_list[2]
content = read_s3_object(bucket_name, object_key)
res = notify2slack(m_from, subject, date, content, object_key)
logger.info("Response: " + str(res))
def read_s3_object(bucket_name, object_key):
"""
Read files From S3.
Parameters
----------
bucket_name : string
Bucket Name
object_key : string
File Name ( Path )
Returns
-------
body : dict
API Return Values
"""
s3 = boto3.client("s3")
try:
res = s3.get_object(
Bucket=bucket_name,
Key=object_key
)
logger.info("Success: %s", res)
body = res['Body'].read().decode('utf-8')
except Exception as e:
logger.error("Error: %s", e)
return body
def notify2slack(m_from, subject, date, content, object_key):
"""
Notify messages to slack.
Parameters
----------
m_from : string
Mail From
subject : string
Mail Subject
date : string
Mail Date
content : string
Mail Content
object_key : string
File Name ( Path )
Returns
-------
res : dict
API Return Values
"""
slack_message = {
"channel": os.environ['channelName'],
"icon_emoji": ":rotating_light:",
"attachments": [
{
"color": "#FF0000",
"title": "Email has been received.",
"text": "<!here> \n *Content* \n ```%s``` \n" % (content),
"fields": [
{
"title": "Date",
"value": date,
"short": True
},
{
"title": "Subject",
"value": subject,
"short": True
},
{
"title": "From",
"value": m_from,
"short": True
},
{
"title": "object_key",
"value": object_key,
"short": True
}
]
}
]
}
req = Request(decrypt_hookurl(os.environ['HookUrl']), json.dumps(slack_message).encode('utf-8'))
try:
res = urlopen(req)
res.read()
logger.info("Message posted to %s", slack_message['channel'])
except HTTPError as e:
logger.error("Request failed: %d %s", e.code, e.reason)
except URLError as e:
logger.error("Server connection failed: %s", e.reason)
return res
def decrypt_hookurl(hookurl):
"""
Notify messages to slack.
Parameters
----------
hookurl : string
WebhookURL that may be encrypted
Returns
-------
hookurl : string
WebhookURL
decrypted_hookurl : string
Decrypted WebhookURL
"""
if "hooks.slack.com" in hookurl:
logger.info("HookURL is not Encrypted")
return hookurl
else:
logger.info("HookURL is Encrypted")
decrypted_hookurl = boto3.client('kms').decrypt(
CiphertextBlob=b64decode(hookurl),
EncryptionContext={'LambdaFunctionName': os.environ['AWS_LAMBDA_FUNCTION_NAME']}
)['Plaintext'].decode('utf-8')
return decrypted_hookurl
最後に
このブログを始めて、もう少しで 5 年が経過しそうです。
※ IT 業界で働きだしたのが 3 月なので、今月で丁度 5 年になります。
あくまでも自分の備忘録として存在しているサイトですので、稚拙な内容に関しては何卒ご容赦頂けると幸いでございます…。
引き続きどうぞよろしくお願いいたします。(•ᵕᴗᵕ•)
